Calculating 95th Percentile
(2018-04-05)
TL/DR:
If you want something done right, you have to check the math and be willing to do it yourself.
...or, a descent into madness
So we have a new internet service provider. Unlike our previous connections, this new connection is a burstable connection. In this context, what 'burstable' means is that we have a 1Gb/s link to our ISP, and we pay a fixed rate as long as our 95th percentile usage is 300 Mb/s or lower. If it is higher, we can either raise the 95th threshold, or pay overages fees.
Now because I'm a networking wonk I've been playing with a bunch of tools (some open source, some tediously banged together by me) with which I try to be able to answer some basic questions:
- what is our networking usage?
- who is using what?
- why was the network slow yesterday?
To that list of questions I can now add:
- what is our 95th percentile usage for last month?
The Easiest Answer Is Always Wrong
So that should be easy, right? I'm looking at our head-end router cluster through LibreNMS, and all I have to do is count the bytes going through the (virtual) physical interface that carries all of, and only, internet traffic, right?
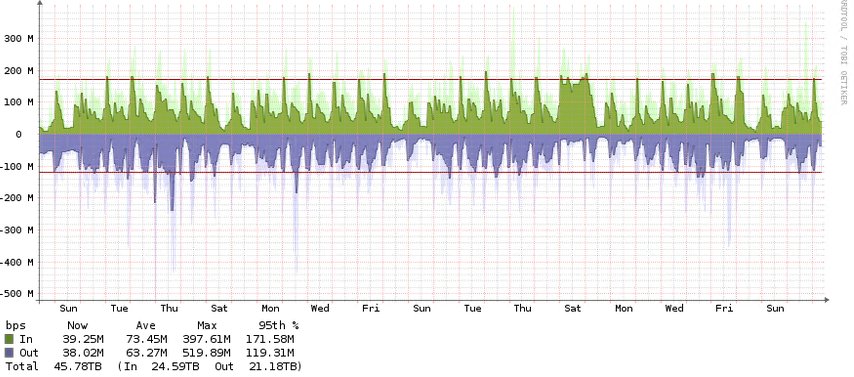
Hey, it even provides 95th percentile information!
Done, right?
No.
There are three things wrong with this information.
What Is 95th Percentile?
First of all, the definition of '95th Percentile' as implemented here is incorrect.
Wikipedia lists three possible definitions for the term 95th percentile. For the purposes of our usage, we are going to use this one:
Take the sum(in, out) for each interval.
This method accounts for variances in input and output and makes the values related to the amount of data transferred in a given window.
The window most commonly used in my experience is five minutes. So every five minutes, the ISP reads the number of bytes you have transferred in the previous five minutes, does some math to change that into bits per second (which we'll get to) and stores that value for the given interval.
Since our LibreNMS graph has two lines for the 95th percentile, the displayed value is of no practical use to us.
RRD Doesn't Calculate 95th Percentile The Same Way We Want To
So okay, given that what I did is go back to my source data. Along with LibreNMS, I am using fprobe to generate nfdump flow files, which I can then process with nfsen for interesting information. Nfsen uses RRD to keep track of byte counts for sources, so I figured I could just use the RRDs that Nfsen generated and calculate my 95th percentile value from that.
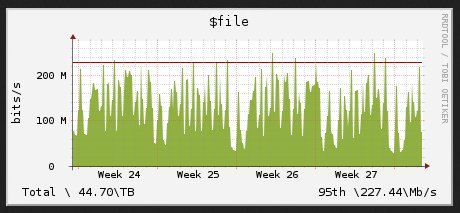
Unfortunately, the answer that you get when you do this depends on the width of the graph you draw. The magic to draw the graph is this:
/usr/bin/rrdtool graph /var/www/html/95th/$FILE.png
--imgformat=PNG
--start='$from'
--end='$to'
--pango-markup
--title='$file'
--vertical-label='bits/s'
--slope-mode
--base=1000
--height=125
--width=350
--alt-autoscale-max
--lower-limit='0'
--slope-mode
DEF:bytes1='/var/lib/netflow/nfsen-1.3.8/profiles-stat/live/RDC1.rrd':'traffic':AVERAGE
DEF:bytes2='/var/lib/netflow/nfsen-1.3.8/profiles-stat/live/RDC2.rrd':'traffic':AVERAGE
CDEF:bits1=bytes1,8,*
CDEF:bits2=bytes2,8,*
CDEF:total=bits1,bits2,+
CDEF:rTotal=bytes1,bytes2,+
VDEF:transfer=rTotal,TOTAL
VDEF:95th=total,95,PERCENT
AREA:total#90B040:
GPRINT:transfer:'Total %6.2lf%sB '
LINE1:95th#aa0000
GPRINT:95th:'95th %6.2lf%sb/s' > /dev/null
What it turns out is happening is that rrdtool looks at the data window you are providing and at the width of the requested graph, and from that computes the number of data points needed to draw that graph. And then -- and this is the key thing -- computes the 95th percentile based on the datapoints used in the graph, not the dataset provided.
Which is a long way of saying: 95th percentile calculation happens after aggregation, not before.
I proved this by changing the geometry of the graph drawn from a given dataset from a width of 350 to a width of 3500 and I got a significantly different number.
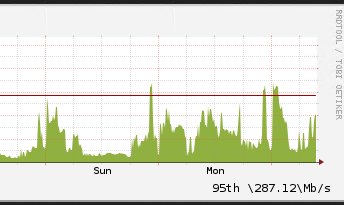
So this line I've convinced rrdtool to draw for me is also effectively meaningless.
Sidebar
The reason why this post-aggregate calculation doesn't affect numbers in terms of throughput is because most of the time you will be using the AVERAGE method to aggregate, and the sum of a given set of datapoints will be roughly the same as the product of the average of those datapoints times the number of datapoints provided.
For the 95th, we specifically care about large outliers of the sort which are going to get lopped off when averaged.
Your RRD probably doesn't have the data you need anyways
The third problem with this data is that we are probably not creating the RRDs in such a way to keep enough datapoints to calculate the 95th percentile problem.
When you define a RRD you are defining the rules for how data moves through the database as it ages. The older it gets, the more it gets aggregated down.
I already have a script which walks the netflows and generates per-IP RRDs consisting of in and out byte counts. So all I had to do was modify it so that every time it added a byte count to a give IP address, it added it to a special IP address called TOTAL. That would give me a RRD which had the total bytes in and the total bytes out in a given time period, and after a certain amount of mucking about, I persuaded rrdtool to draw me a line representing the 95th percentile of a given data set. Based on some cacti work I'd done in the past, my RRDs were being defined like this:
RRDs::create ("$RRD/$ip.rrd", "--start=$creationTime",
"DS:bitsIn:GAUGE:300:U:U",
"DS:bitsOut:GAUGE:300:U:U",
"RRA:AVERAGE:0.5:1:600",
"RRA:AVERAGE:0.5:6:700",
"RRA:AVERAGE:0.5:24:775",
"RRA:AVERAGE:0.5:288:797",
"RRA:MAX:0.5:1:600",
"RRA:MAX:0.5:6:700",
"RRA:MAX:0.5:24:775",
"RRA:MAX:0.5:288:797");
The pertinent part of this definition is the first RRA line, where we're saying keep 1 record for only 600 slots (where a slot is 300 seconds long, as defined in the DS line).
This means that the oldest un-aggregated five-minute value can be no more than 50 hours old, and a month is a lot longer than 50 hours. So we're aggregating our data away even before rrd can incorrectly calculate it.
And the nfsen-generated RRDs are similarly constructed. There's no need to keep high resolution data to display monthly or weekly graphs, so it gets aggregated away very quickly.
Now a person like me would say, well then let's just boost the number of timeslots to keep 12 * 24 * 32 elements of data -- that's 32 days of data for those of you playing along -- and we're golden, right?
Well, wrong. We're now keeping 9216 timeslots, so in order to ensure our calculated 95th percentile value accurate, our graph has to be 9216 pixels wide, otherwise we get bit by the post-aggregation-calculation problem. And scaling that down loses some of the text and graph peak resolution.
So I guess techically we can make a graph with a correct value on it, just not one of any practical use.
So rrdtool is a bust for this
Back to square one.
Fortunately back on square one I already have a separate process for reading nfcap files, finding traffic related to my local IPs, and collecting them for the purposes of A) graphing per-IP graphs, and B) generating per-IP and per-customer monthly traffic totals. We don't actually bill based on this information -- hosting is billed based on other criterea -- but it behooves us to keep an eye on which customers are passing large amounts of data so that we can possibly alert them when their data profile sharply changes or we can stop them from doing things that are unfriendly to the rest of our user base.
As a result of this, I have a postgresql database that contains five-minute interval traffic, in and out, for each of my public IPs. I did it this way because it was the easiest way and because before I did the math above I didn't trust RRD to keep the data resolution I wanted it to. This database is, as you'd expect, pretty large, so mining it for data can take some time.
So what I needed to do was to construct a SQL query that took the sum (in plus out) of traffic for all my public IPs, ranked them in numerical order, figured out which sample period represented the 95% percentile, convert it to a bits-per-second value, and return that.
Easy, right?
Well, given a start and a finish time (ie midnight on the first, and 23:59 on the last day of the month), we can construct a query as so:
select row_number () over (order by sum(bytesIn + bytesOut) desc) as rn, \
timeslot, \
sum(bytesIn + bytesOut) as Total \
from rdc_localip $timeslot \
group by timeslot order by total \
desc limit 1 offset (select (count(distinct timeslot)*0.05)::numeric::integer from rdc_localip $timeslot);
So this returns a single row consisting of the row number of sorted output, the timeslot of the row in this row number, and the sum of all bytes in and all bytes out in this timeslot -- sorted by the total bytes per timeslot descending.
We calculate the row to return by selecting a single row (desc limit one) offset 5% into the sorted list by counting the number of distinct timeslots (one per row: (count(distinct timeslot)*0.05)::numeric::integer). By using integer, we're rounding the number down, which should bias the value we report up; so if there is an error here, our reported value should always be higher than the number reported by our ISP.
And because the time selector is repeated code, it is in the query above as $timeslot, and is built this way:
if ($BEFORE)
{
$until = "timeslot < " . str2time("$BEFORE $TZ");
$timeslot = "where $until";
}
if ($AFTER)
{
$from = "timeslot > " . str2time("$AFTER $TZ");
$timeslot = "where $from";
}
if ($BEFORE and $AFTER)
{
$timeslot = "$timeslot and $until";
}
We then calculate the bits per second value for this timeslot as so:
$Mbs=$totalBytes * 8 /1000 /1000 /60 /5;
So that's
- multiply by 8 to get bits per timeslot
- divide by 1000 to get killobits per timeslot
- divide by 1000 to get megabits per timeslot
- divide by 5 to get megabits per minute
- divide 60 to get megabits per second
Note that we're using base-10 Mb/s, not base-2.
...and this, as far as I can tell, works at least for the monthly case.
One other thing to note: in my case, the timeslot of the five minute interval is not the edge of the five minutes, it is somewhere in between. That way you can select fenceposts as the BEFORE and AFTER time periods and not worry about inadvertently collecting the first five minutes of the next month when you run the report.
Conclusion
And the grand result is a perl script that outputs this:
$ time ./95th -m
Warning: assuming --profile profile.rdc
Month Starting 2018-06-01 300.973513093333 Mb/s
(Record 433)
real 0m28.970s
user 0m0.039s
sys 0m0.017s
So in my case this involves several million records, and the query runs in about 30 seconds. I have written a more complicated report generator that pulls the customer assignment information out of our phpipam, and then generates 95th percentile values for each customer. Naturally this takes much longer to run since you have to select a list of IPs and then do math on them for each timeslot, order the resulting timeslots, and select the 95th percentile of that. Although to date, our in-house operations of email and backup offsiting far exceeds any other customer traffic flows.
TL/DR:
If you want something done right, you have to check the math and be willing to do it yourself.